Multi-Token Prediction (MTP) merged into llama.cpp main on May 16, 2026. I deployed it to my production stack the next day, and within hours hit something that didn't match the "free speedup" framing the feature gets in release notes: with the stock default, my Qwen3.6 35B MoE got slower. Not marginally — it dropped from 53 tokens/second to 13. A 75% loss, from turning on a feature that's supposed to make generation faster.
The default was the problem. And after a week of controlled measurement — 260 benchmark runs across two model architectures, eight draft depths (from zero to sixteen), five workload types, two sampler configurations, and three speculation-pipeline chains — I can map exactly where the trap is, where the real sweet spots are, and why the answer is different for dense models than for mixture-of-experts.
This is the focused tuning post. Full-context decode behavior (where things get even more interesting) is the next one.
What MTP is, in one paragraph
Speculative decoding speeds up generation by having a small, cheap "draft" model propose several tokens ahead, then verifying them in a single batched forward pass of the full model. If the drafts are accepted, you got multiple tokens for roughly the cost of one. MTP is a variant where the draft tokens come from a lightweight prediction head baked into the model itself, rather than a separate draft model. Qwen3 ships with one such head. The key tuning knob is --spec-draft-n-max: how many tokens the draft head proposes per round. More drafts means more potential parallelism — but also a bigger, more expensive verification batch, and lower odds that the whole speculative sequence gets accepted.
That tension — more drafts versus bigger verify — is the entire story.
Scope: this is a Qwen3 finding
Before the numbers, an honest boundary. As of llama.cpp b9295 (the build all measurements below run on), --spec-type draft-mtp is fully wired end-to-end only for the Qwen3 family (the qwen35 and qwen35moe architectures). Several other model families — DeepSeek-V3, GLM-4, EXAONE-MoE, Ling/Bailing, MiMo-2 — ship MTP-head tensors in their GGUFs and have their metadata read by their respective loaders, but none of them have an MTP decoder graph implemented upstream. Attempting --spec-type draft-mtp on those will fail at context creation. The code even hardcodes GGML_ASSERT(nextn_predict_layers == 1) — single MTP head only. Meta's Llama, Google's Gemma, and Mistral don't include MTP heads at pretraining at all.
So everything here is "Qwen3 MTP on Vulkan, on a Strix Halo iGPU." The mechanism generalizes; the specific numbers are for this hardware and this model family.
The hardware is the same Bosgame M5 (Ryzen AI MAX+ 395, gfx1151, 96 GB unified VRAM) from the previous posts, on Vulkan/RADV. ROCm isn't an option here — that board reproduces ROCm Issue #6182 in every configuration I tested, which was the entire subject of the last post. MTP on ROCm is an open follow-up for whenever that bug gets fixed upstream.
The trap, drawn as a curve
Here's the n_max sweep for both models, generation throughput against draft depth, controlled measurements (five runs per cell, first run dropped as warmup, median of the remaining four):
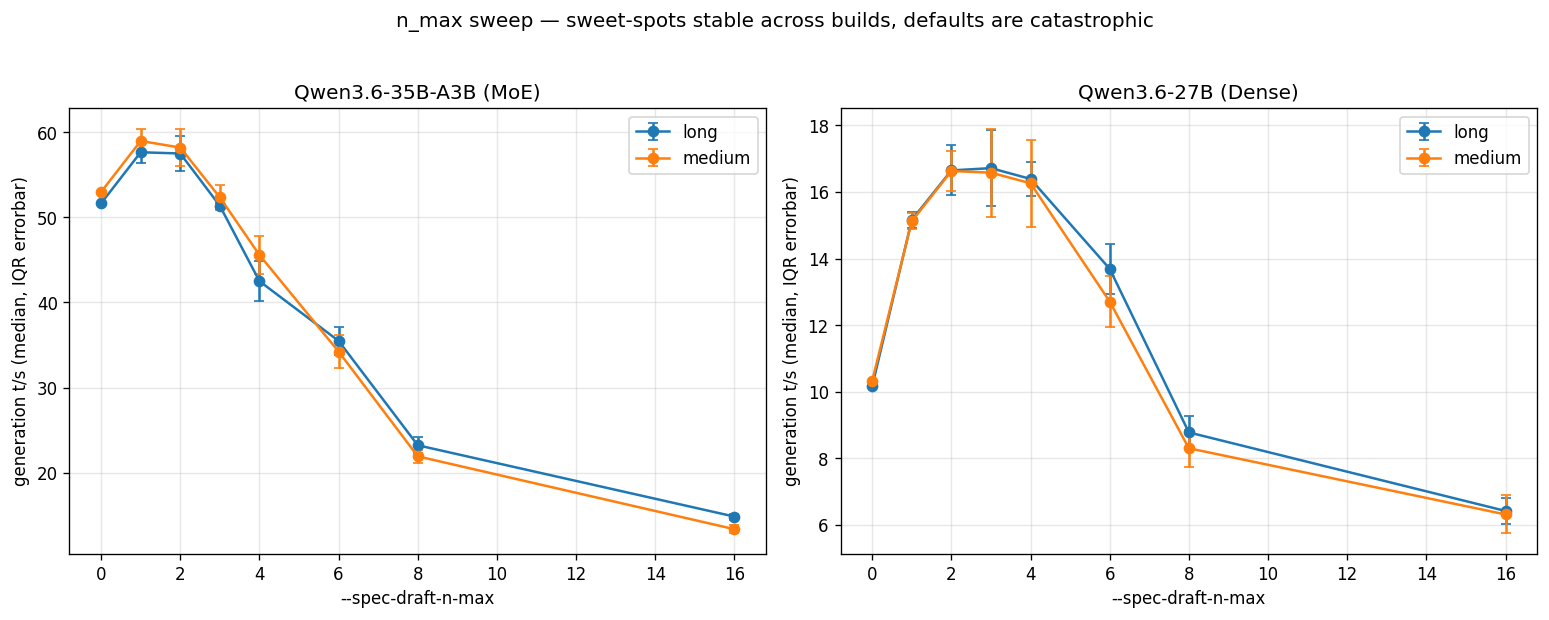
The shape is the headline. Both curves rise sharply from baseline, peak early, then collapse. The collapse is the trap, and the old default n_max=16 sits deep inside it.
For the 27B dense model:
| --spec-draft-n-max | gen t/s (medium) | vs baseline |
|---|---|---|
| 0 (no MTP) | 10.33 | — |
| 1 | 15.12 | +47% |
| 2 | 16.63 | +61% |
| 3 (new default) | 16.58 | +61% |
| 4 | 16.26 | +57% |
| 6 | 12.71 | +23% |
| 8 | 8.30 | −20% |
| 16 (old default) | 6.31 | −39% |
For the 35B-A3B MoE model:
| --spec-draft-n-max | gen t/s (medium) | vs baseline |
|---|---|---|
| 0 (no MTP) | 52.98 | — |
| 1 | 58.97 | +11% |
| 2 (sweet spot) | 58.20 | +10% |
| 3 (new default) | 52.34 | ~baseline |
| 4 | 45.58 | −14% |
| 6 | 34.22 | −35% |
| 8 | 21.92 | −59% |
| 16 (old default) | 13.35 | −75% |
Two things jump out. First, the dense model gets a huge win from MTP at the right depth (+61%) and the MoE model gets a modest one (+10%). Second, both models are worse than no MTP at all by n_max=8, and catastrophically worse at the old default of 16. On the dense model, n_max=16 with the long prompt also pushed the GPU past 85°C and triggered thermal throttling — the only place in the whole sweep that happened.
If you turned MTP on with stock settings before May 19 and benchmarked it once, you'd have concluded MTP makes Qwen3 dramatically slower and turned it back off. The feature works. The default was sabotaging it.
Upstream agreed, three days later
I found these sweet spots on May 17-18. On May 19, llama.cpp PR #23269 reduced the --spec-draft-n-max default from 16 to 3. The maintainers reached the same conclusion independently: 16 was too aggressive for single-head MTP.
That new default of 3 is a good choice for the dense model — it lands right on the plateau (+61%, statistically tied with n=2). It's a mediocre choice for the MoE model, where n=3 is already back down to roughly baseline and the actual peak is n=2. Which is the real lesson: a scalar default cannot be right for both architectures. The dense model wants n=3, the MoE model wants n=2, and the difference isn't noise — it's mechanistic.
Why dense and MoE want different depths
The classic speculative-decoding speedup model (Leviathan et al., 2023) gives expected speedup as a function of acceptance rate α and the draft/target cost ratio c:
speedup = (1 − α^(γ+1)) / ((1 − α)(c·γ + 1))
where γ is the number of draft tokens. This is a useful lens, with one honest caveat: I'm not deriving c from first principles. Our dense model's measured acceptance rate is α ≈ 0.63, and the value of c that makes Leviathan's formula peak at our observed sweet spot is ≈ 0.12. That's worth stating plainly rather than dressing up as "theory predicts the data" — it's a one-parameter fit. What's interesting is that the fitted c ≈ 0.12 is several times larger than the MTP head's raw parameter ratio alone would suggest, which is consistent with the draft path carrying real overhead beyond the head itself (sampling, batch setup, verification logic). The formula isn't proving the sweet spot; it's giving a coherent frame for why a sweet spot exists at all and why it sits where it does.
The rapid collapse past the peak comes from a second effect. Qwen3 has a single MTP head, called autoregressively to produce each successive draft token. Each step feeds on the previous one, so errors compound: the acceptance rate for the k-th draft token falls off geometrically, faster than a multi-head approach like Medusa would. By the time you're asking for 8 or 16 drafts, almost none of the tail gets accepted, and you've paid full verification cost for a batch that's mostly thrown away.
The MoE model needs its own explanation, and this is the part I haven't found treated in the literature. The speculative-decoding papers — Leviathan, Medusa, the EAGLE series — all assume a dense target. For a mixture-of-experts target, the draft/target cost ratio c isn't constant in γ. Here's why: during verification, the model processes γ+1 tokens in a single batch, and each token routes to its own subset of experts. A mixture-of-experts model activates only a small fraction of its total experts per token — but as the verify batch grows, the union of experts activated across the batch grows too. The effective active fraction of the model rises super-linearly with the number of draft tokens. So the MoE's verification gets disproportionately expensive as you add drafts, the cost ratio c rises with γ, and the optimum shifts left, toward fewer drafts. That's why the MoE sweet spot is n=2 while the dense sweet spot is n=3.
This is an approximation — draft tokens from a single MTP head share semantic context, so their expert routing is correlated and the real union grows more slowly than fully-independent routing would. But the qualitative super-linear scaling holds, and it's the direction that matters for the sweet-spot shift. I'm calling this verify-batch expert-union growth. If someone has seen it formalized somewhere, I'd genuinely like the reference; as of this writing I haven't found one.
The sweet spots don't move when the code does
The strongest evidence that the optimum is set by architecture, not by some incidental code-path detail, is that the sweet spots held stable across four build generations over six days of fast-moving upstream development, even as the absolute speedups climbed:
| Build | Date | MoE n=2 speedup | Dense sweet-spot speedup |
|---|---|---|---|
| b9199 | May 17 | +9.7% | +80% (at n=4) |
| b9219 | May 18 | +8.4% | +66% (at n=4) |
| b9235 | May 19 | +13.8% | +72% (at n=3) |
| b9295 | May 23 | +17.4% | +81% (at n=3) |
Three MTP-related optimizations landed across those builds (backend sampling for the draft path, skipped logit computation, a draft-resource leak fix). Every one of them improved the height of the peak — but none moved its location. The MoE optimum stayed at n=2, the dense optimum stayed at n=2-3, throughout. That's exactly what you'd expect if the optimum is fixed by the architecture's verify-cost-versus-acceptance trade-off, and the code optimizations are just lowering verify cost across the board. (These trajectory figures are single-run production measurements, not the controlled n=4 medians above — directionally solid, not publication-grade per cell.)
Workload type matters more than prompt length
At the sweet-spot depth, I swept five workload types — code, structured text, technical writing, creative writing, dialog — each as a ~600-token prompt:
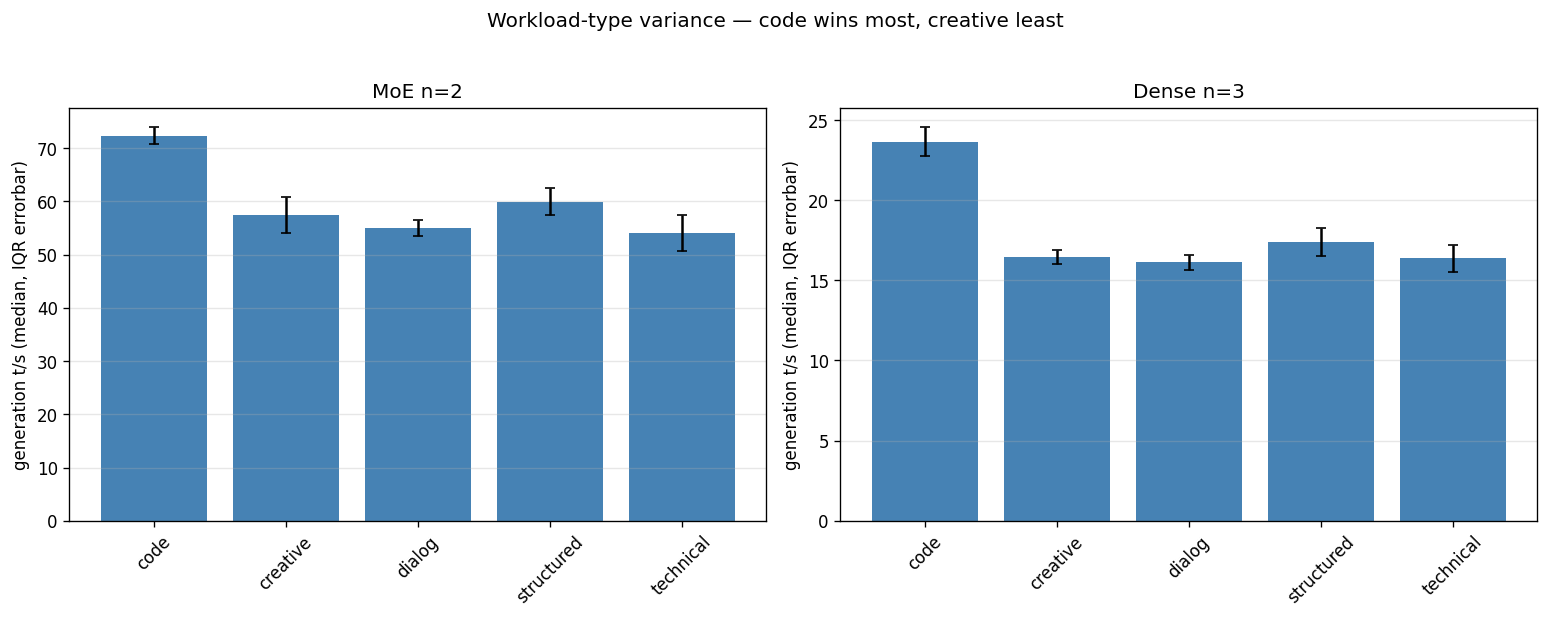
Code dominates, on both models:
| Workload | Dense (n=3) | MoE (n=2) |
|---|---|---|
| Code (Python BST) | +129% | +37% |
| Structured (history) | +68% | +13% |
| Technical (comparison) | +58% | +2% |
| Creative (essay) | +59% | +8% |
| Dialog | +56% | +4% |
The dense model writing code at +129% over baseline is the single strongest result in the entire benchmark — a 23.65 t/s median versus 10.33 t/s with no MTP. The reason is intuitive once stated: code is locally predictable. Closing brackets, repeated identifiers, boilerplate structure, conventional indentation — the MTP head guesses these correctly far more often than it guesses the next word of an essay. High acceptance rate means more of the draft batch survives verification, means more tokens per forward pass.
The practical read: MTP's value depends heavily on what you're generating. If your workload is coding-agent traffic, the speedup is large. If it's open-ended prose, it's modest. Prompt length, by contrast, barely mattered — the medium (461-token) and long (3799-token) prompts gave nearly identical speedups at every depth. Content type is the variable that moves the needle.
The sampler quietly taxes your speedup
One coupling that's easy to miss: your sampler settings affect MTP acceptance. I run presence-penalty=1.5 in production for output-quality reasons. Comparing it against presence-penalty=0.0 at the sweet-spot depth:
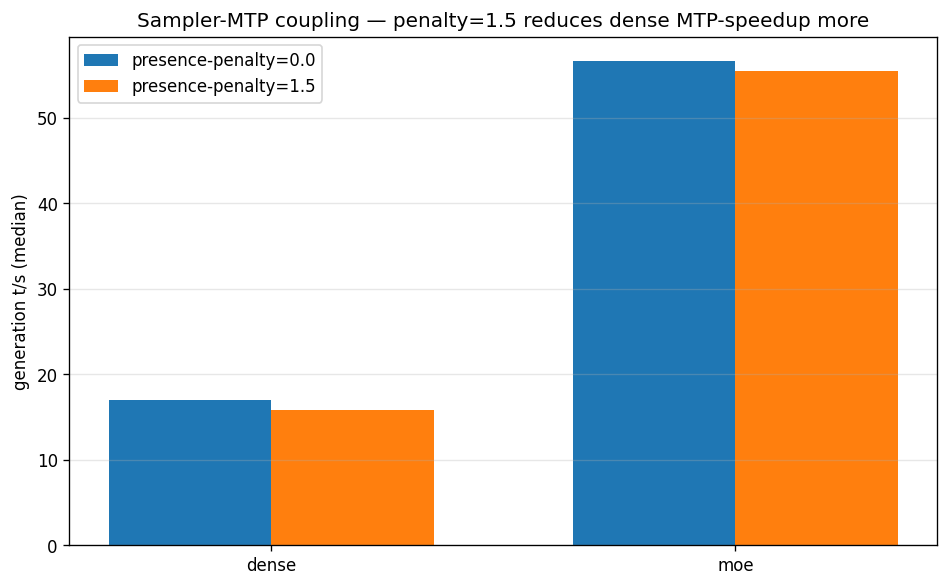
| Model | penalty 0.0 | penalty 1.5 | delta |
|---|---|---|---|
| 27B Dense (n=3) | 17.03 | 15.81 | −7.2% |
| 35B-A3B MoE (n=2) | 56.65 | 55.51 | −2.0% |
The dense model loses about 3.6× more speedup to the aggressive penalty than the MoE model does. The likely mechanism: the same penalty configuration is applied when the draft head generates and again at verification, so an aggressive presence-penalty pushes the draft head toward tokens that then get rejected at verify — acceptance drops. I haven't traced this through common/speculative.cpp to confirm the draft path and main path share the exact sampler chain, so treat that as the plausible explanation rather than a verified one; the empirical effect is what we measure. On the dense model that lost acceptance translates fairly directly to lost throughput. On the MoE model, the dominant verification cost absorbs most of the sampler overhead, so the effect is smaller.
This doesn't change my production config — I keep penalty=1.5 because output quality matters more than 7% of speed for my cron and agent workloads. Quality is hard to put a number on, but it shows up indirectly: fewer failed cron-job outputs, fewer agent retry-loops. But it's worth knowing the trade exists and roughly how big it is, because nobody mentions it: your quality knobs and your speed knobs are coupled through the draft path.
Chaining drafters doesn't help here
PR #23269 also enabled chaining multiple speculation methods — running MTP alongside n-gram-based drafters in a single pipeline. The pitch is that different drafters catch different patterns. I tested MTP alone against MTP+ngram-mod and MTP+ngram-mod+ngram-map-k4v, at sweet-spot depth:
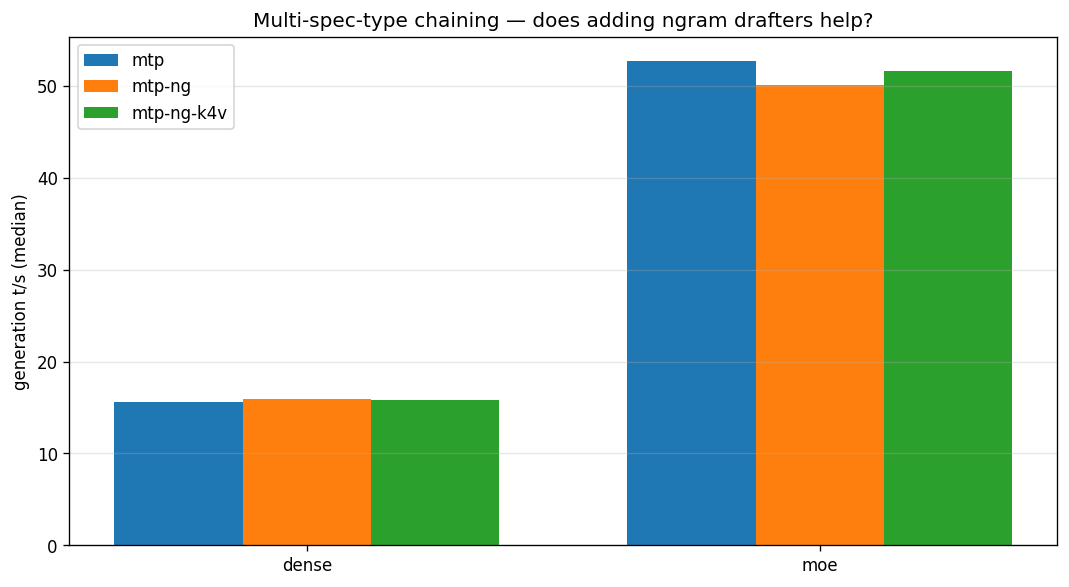
| Model | MTP only | + ngram-mod | + both ngrams |
|---|---|---|---|
| 27B Dense | 15.60 | 15.95 (+2.2%) | 15.81 (+1.3%) |
| 35B-A3B MoE | 52.73 | 50.11 (−5.0%) | 51.63 (−2.1%) |
The verdict for this hardware: chaining isn't worth it. The dense model's 1-2% gain is within noise; the MoE model measurably loses. On a single integrated GPU with one Vulkan queue, the extra drafters compete for the same compute the verification pass needs, and that competition outweighs the marginal acceptance gain. This isn't necessarily a universal result — PR #23269 cites a community user reporting 75 t/s on a dual 5070 Ti with chained configs, which is suggestive but not isolated (we don't know how much of that came from chaining versus MTP alone). The plausible read is that multi-GPU setups have spare compute the chained drafters can use without competing with verification, headroom that a single-queue iGPU doesn't have. On a Strix Halo box, stick with --spec-type draft-mtp alone.
What to actually set
If you're running Qwen3 MTP on a Strix Halo box (or similar single-GPU Vulkan hardware):
- MoE models (like 35B-A3B):
--spec-draft-n-max 2. The new upstream default of 3 leaves ~10% of speedup on the table for MoE. - Dense models (like 27B):
--spec-draft-n-max 3. The new default is correct here. - Never leave it at the old 16 if you somehow pinned an older build — it's catastrophic on single-head MTP.
- Don't chain drafters on single-GPU Vulkan. One MTP path is the whole win.
- Expect content-dependent results. Code generation gets the biggest lift by a wide margin; prose gets a modest one.
- Know your sampler costs you a few percent of MTP speedup if you run aggressive penalties — worth it for quality, but quantify it for your own workload.
What I didn't measure
Deliberately scoped out, mostly because they're the next post:
- Full-context decode behavior. Everything above is at modest context (≤3800 tokens). What happens to MTP speedup at 30k, 60k, 76k tokens of context is a separate and more dramatic story — that's the next post, reproducing and extending kmarble's full-context findings.
- Quantization depth. All measurements are at UD-Q5_K_XL. Whether the sweet spots shift at Q4 or Q8 is untested.
- ROCm. Not possible on this board (Issue #6182). When that's fixed upstream, the MoE expert-union effect might look different on a different backend.
- Per-position acceptance rates. llama.cpp reports aggregate acceptance, not per-draft-position. The geometric-decay claim is inferred from the n_max curve shape, not measured directly per position.
All the raw data — 260 runs, four charts, the full methodology, the bench scripts — is in the companion repo at github.com/thefrontierlab/post4-bench. If you reproduce different sweet spots on different Qwen3 quants or different hardware, I'd like to hear about it.
Coming up: MTP at full context. At modest context lengths the speedup is well-behaved. At 76k tokens it is not — and the backend you're on determines whether generation throughput holds steady or collapses by two-thirds. That's the next bench.
Discussion